1 引言
深度学习可以表示非常复杂的函数,甚至是从一个图片映射为另一个图片。这个函数可以用于很多任务:例如动漫画稿的自动上色、自动化妆、卫星图片转为地图等。
这里有一个专门的网站:http://paintschainer.preferred.tech/index_zh.html
2 原理
按照GAN的标准思路[1],使用一个生成器生成图片,然后使用一个判别器判断图片是否是生成的图片。生成器试图欺骗判别器,而判别器则努力区分真实图片与生成图片,训练过程中两者互相博弈。
生成器G的网络结构是一个U-net。第一部分通过CNN先将size缩小,增加通道维度;第二部分再对size进行扩展,直到与原图像大小相同,通道相同。为了更直接的获取原图像的信息,将第一部分的特征直连到第二部分的相应层的输出上。
值得一提的是,与一些直接使用亮度或者轮廓信息的方法不同,这里可以使用一个模糊后的颜色图片加入输入,因此输入可以有4个维度的信息。相当于在使用的时候除了图片信息,还要使用一些提示,例如在图片上大致位置上勾勒一下相应位置的颜色,但是颜色位置并不需要太精确。
判别器D的网络结构是标准的CNN分类模型。再CGAN中,通过判断两个图片对是真实的还是生成的,模型中可以直接将输入图片与生成图片(真实图片)进行直接拼接作为判别器的输入。
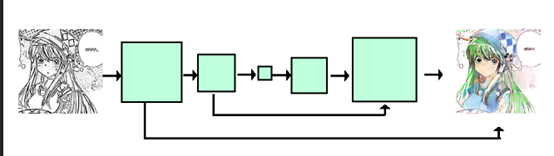
3 其他模型
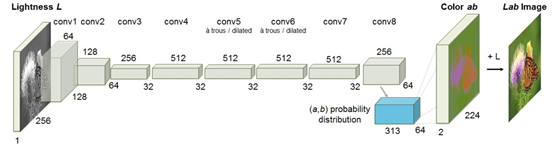
另外,还有一些利用亮度信息对图片进行上色的模型[2]。图片采用LAB的编码形式,L代表了亮度信息,从0~100,而AB是两维颜色空间,输入A表示从红色到绿色的范围,取值范围是[127,-128];B表示从黄色到蓝色的范围,取值范围是[127,-128]。
整个模型的输入是图片的亮度。模型包含了8层中间层,1层输出层,结构都是卷积层。输出是AB通道的预测结果,通过将L与AB通道拼接得到上色的图片。损失函数使用的是MSE。
为了提高效果,还可以使用VGG等预先训练好的分类模型,提取图片的特征,使用Repeat操作后与CNN得到的特征进行拼接。
一些生成结果

来看一下进化的过程:
-
漫画自动上色


(2)黑白照片转为有色照片





当然我也发现在照片特别多的情况下这个网络表现的并不是很好。这应该是普通GAN的通病,难以处理类别多的情况,但是对于单一类别或者少量类别的情况就效果很好。例如当图片类别多的情况下,就只能停留在下面这个图片上的水平。

然而直接使用MSE或者MAE作为优化函数的话,会得到更加奇怪的效果:

似乎模型已经偏向于使用了一个平均的颜色(铜色)。
将照片转化为漫画风格
如果我把图片的轮廓提取出来,在给定一个模糊的颜色,那么就可以利用这个模型将照片转化为漫画风格的图片了。
我们来看看效果。


再来一张:


好像把牙齿当成了嘴唇。哈哈。
参考
[1]博客地址http://kvfrans.com/coloring-and-shading-line-art-automatically-through-conditional-gans/
代码:
https://github.com/kvfrans/deepcolor
https://github.com/phillipi/pix2pix
https://zhuanlan.zhihu.com/p/25709644
https://github.com/williamFalcon/pix2pix-keras
[2] 基准模型:Zhang R, Isola P, Efros A A. Colorful Image Colorization[J]. 2016:649-666.
加入类别特征的模型:Razavian A S, Azizpour H, Sullivan J, et al. CNN features off-the-shelf : An Astounding Baseline for Recognition[J]. 2014:512-519.
https://github.com/baldassarreFe/deep-koalarization
https://blog.floydhub.com/colorizing-b&w-photos-with-neural-networks/
推荐:
https://github.com/junyanz/interactive-deep-colorization
数据